CS 144 Checkpoint 0 - Byte Stream

“Welcome to CS144: Introduction to Computer Networking. In this warmup, you will set up an installation of Linux on your computer, learn how to perform some tasks over the Internet by hand, write a small program in C++ that fetches a Web page over the Internet, and implement (in memory) one of the key abstractions of networking: a reliable stream of bytes between a writer and a reader.”
Writing webget
This is a little introductory project. After reading util/socket.hh, util/file_descriptor.hh and understanding the API, it is not difficult to come up with a working implementation.
void get_URL( const string& host, const string& path )
{
auto socket = TCPSocket();
socket.connect( { host, "http"s } );
socket.write( std::format( "GET {} HTTP/1.1\r\n", path ) );
socket.write( std::format( "Host: {}\r\n", host ) );
socket.write( std::format( "Connection: close\r\n\r\n" ) );
string buffer;
while ( !socket.eof() ) {
socket.read( buffer );
cout << buffer;
}
socket.close();
}We are able to use std::format in C++ 20, which makes the formatting code nicer.
An in-memory reliable byte stream
In this project, we need to implement a single-threaded queue with a fixed capacity. The writer can push some data into the queue, and the reader can read all the data inside the queue and pop some data out.
The std::string_view peek() const operation is the most tricky one, thus it dominates how we design the internal data structure.
A std::string_view is essentially a pair which keeps a pointer to the char array and its length.
struct string_view {
size_t len;
const char* str;
}It does not own the underlying data, it is cheap to copy and slice. More importantly, the underlying data needs to be contiguous, since accessing an element inside a std::string_view is translated to a simple pointer offset.
An obvious choice for the data structure might be std::queue, but unfortunately, there is no way to access its internal data or create a std::string_view from it. (We will get a heap buffer overflow if we attempt hacks like &queue.front(), since by default std::queue is based on std::deque, which is not contiguous.)
std::deque
The next idea is std::deque, which was many people’s choice in the past. However, since std::deque is not contiguous, we cannot simply create a std::string_view from it either. We might attempt to copy its data into a string
std::string_view Reader::peek() const
{
std::string str { begin(buffer_), end(buffer_) };
return str;
}but this produces a use after free error. A std::string_view does not own its data, it’s just a pointer, a “view” over a string. So at the end of peek, the string str goes out of scope and now the returned std::string_view points to a freed string.
There is still a way to make std::deque work, we can try to cheat and just change the function signature to return a std::string instead, and it will compile
std::string Reader::peek() const
{
return { begin(buffer_), end(buffer_) };
}However, this is really slow. Traversing the entire std::deque and creating a copy every time we peek is just too much unnecessary work. I got a whooping 0.09 Gbit/s throughput on my M1 Pro MacBook. (We are so close to 0.1 Gbit/s that passes the test, time to upgrade my laptop! ^^)
std::string
Ok, std::deque is not good enough. If we resorted to returning a std::string after all, why don’t we just try using a std::string as our data structure? A push is just a string concatenation, and conveniently, we have std::basic_string::erase to remove an arbitrary range of characters in our std::string. Now we don’t even need to change the return type of peek, and in fact, we have \(O(1)\) peek for free!
std::string_view Reader::peek() const
{
return buffer_;
}Amazingly, this produced 2.3 Gbit/s on my machine. We just got an easy 25x speed up. It demonstrated how expensive those copies on std::deque were.
Sliding Queue
std::string passes all the tests, but this can’t be the optimal solution right? If we “think from the first principle” and implement our own queue, how fast can it be? We have to use a contiguous base container, so the peek operation can be \(O(1)\), hence std::vector<char> is a straightforward choice. To implement a queue on a std::vector, we can keep two indexes, head_ and tail_ where head_ points to the start of the queue, and tail_ points to the end of the queue. To push elements into the queue, we only need to move the tail_ back and copy the elements in. The time complexity of pushing \(k\) elements is \(O(k)\). To pop elements from the queue, we only need to move back the head_, which is \(O(1)\) regardless of the number of elements we pop.
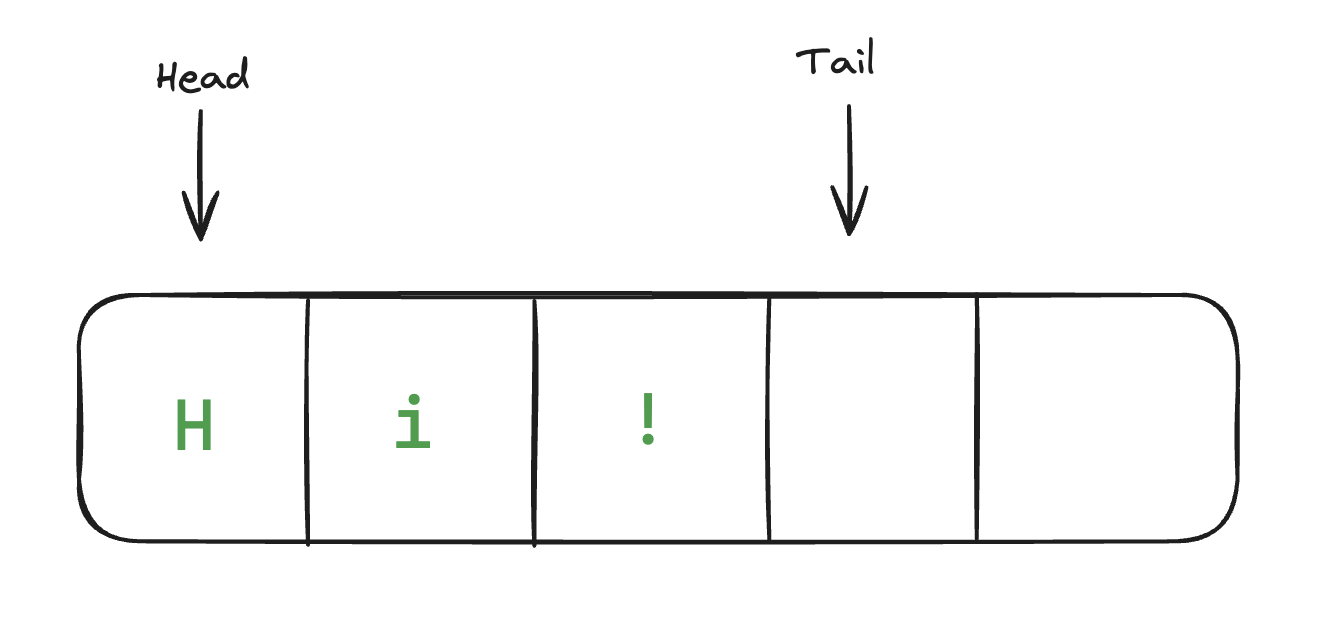
These are all good, but the problem is that after pushing and popping some elements our queue is sliding backwards with respect to its underlying std::vector. So we need a large enough std::vector that allows some “sliding”, and we copy the queue back to the front when we run out of space.
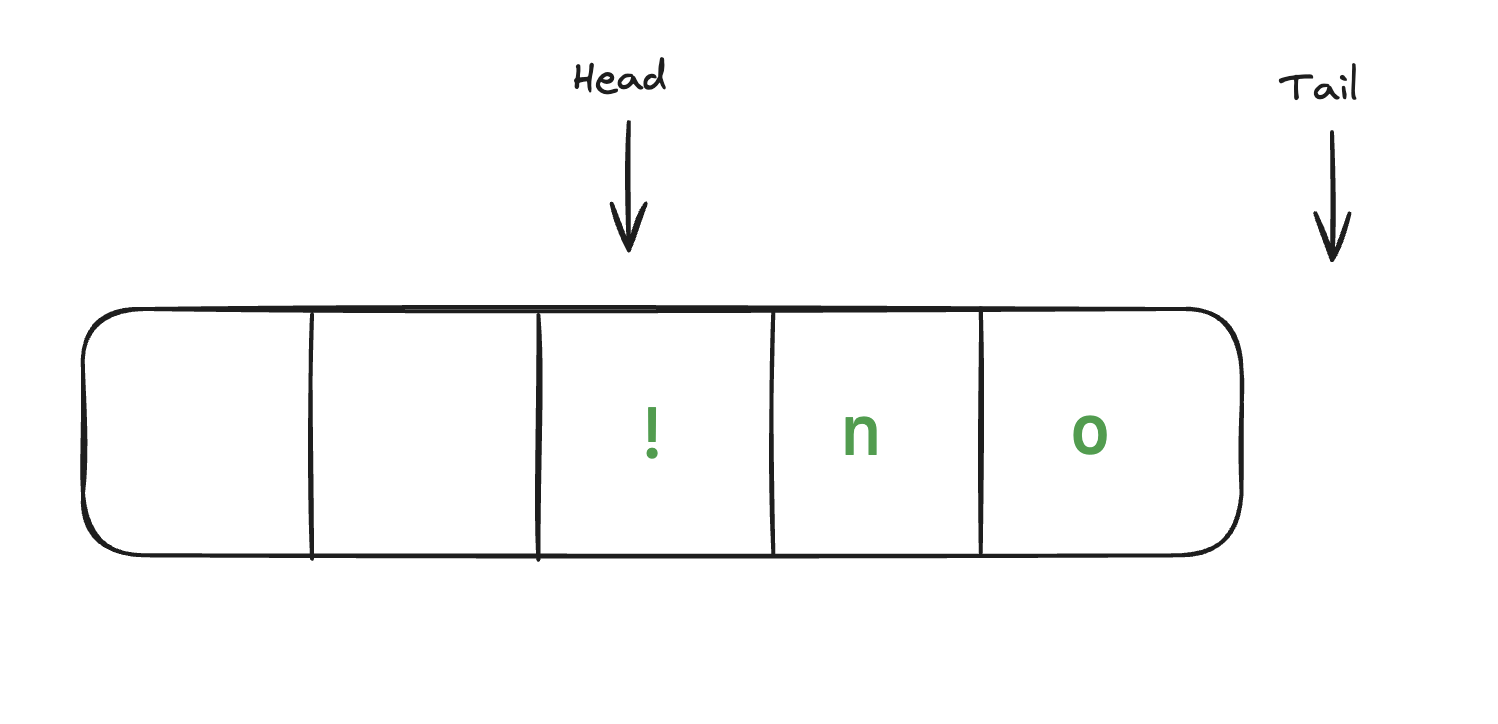
As long as the number of pushing and popping \(p\) we did is proportional to the capacity \(c\), we have amortised \(O(\frac{c}{p})=O(1)\) time complexity for the push and pop operations. In the worst-case scenario, when every push and pop consumes all our capacity, our base std::vector needs to have a size of \(k\times c^2\) and we can still guarantee the amortised \(O(1)\) time complexity.
An implementation of this idea might look like this
class ByteStream
{
// ...
protected:
uint64_t capacity_ {}; // the capacity of the queue
uint64_t size_ {}; // the current size of the queue
uint64_t head_ {}; // point to the head of the queue
uint64_t tail_ {}; // point to one next to the end of the queue
uint64_t copy_mark_ {}; // if head_ >= copy_mark_, we need to move the whole queue back to the start of the buffer_
std::vector<char> buffer_ {}; // the underlying vector
};
void Writer::push( const string &data )
{
// ...
for (size_t i = 0; i < size; i++, tail_++) {
buffer_[tail_] = data[i];
}
// ...
}
void Reader::pop( uint64_t len )
{
// ...
if (head_ >= copy_mark_) {
for (size_t i = 0; i < bytes_buffered(); i++) {
buffer_[i] = buffer_[head_ + i];
}
tail_ -= head_;
head_ = 0;
}
// ...
}This gives a throughput of around 10 Gbit/s, and we again 4x our performance with an optimised data structure. The size of the underlying std::vector matters here. If its size is too small, we need to copy the entire queue more often than necessary; but if it is too large, we will have very bad cache locality. This leaves opportunities for benchmarking and adjusting the parameter for individual machines and workloads.
std::copy
It is a bad idea to copy arrays using raw for loops. After switching both for loops to std::copy, our throughput reached around 30 Gbit/s consistently when the cache is warm.
pcloud@ubuntu:~/minnow$ cmake --build build --target check0
Test project /home/pcloud/minnow/build
Start 1: compile with bug-checkers
1/10 Test #1: compile with bug-checkers ........ Passed 0.09 sec
Start 2: t_webget
2/10 Test #2: t_webget ......................... Passed 1.05 sec
Start 3: byte_stream_basics
3/10 Test #3: byte_stream_basics ............... Passed 0.02 sec
Start 4: byte_stream_capacity
4/10 Test #4: byte_stream_capacity ............. Passed 0.01 sec
Start 5: byte_stream_one_write
5/10 Test #5: byte_stream_one_write ............ Passed 0.01 sec
Start 6: byte_stream_two_writes
6/10 Test #6: byte_stream_two_writes ........... Passed 0.01 sec
Start 7: byte_stream_many_writes
7/10 Test #7: byte_stream_many_writes .......... Passed 1.86 sec
Start 8: byte_stream_stress_test
8/10 Test #8: byte_stream_stress_test .......... Passed 0.36 sec
Start 37: compile with optimization
9/10 Test #37: compile with optimization ........ Passed 0.03 sec
Start 38: byte_stream_speed_test
ByteStream throughput: 30.30 Gbit/s
10/10 Test #38: byte_stream_speed_test ........... Passed 0.07 sec
100% tests passed, 0 tests failed out of 10
Total Test time (real) = 3.50 sec
Built target check0Note that all the benchmarks results shown are just for entertainment. They are not comparable across different machines. The same piece of code has completely different performance on a GitHub Action Runner.
ByteStream with capacity=32768, write_size=1500, read_size=128 reached 23.50 Gbit/s. Test time = 0.06 sec
We achieved more than 300x improvement compared to the original std::deque implementation.
Profiling
At the end of this checkpoint, I profiled our final implementation to see whether the reality matches our analysis.
For the Writer::push method, the memcpy function call takes up all the time. This is as good as it gets, we have to copy the data into the buffer, there is no other way around it.

For the Reader::pop method, the memcpy function call takes up only half of the time. This is good, we get to “sliding” the queue for free half of the time.

Here is the critical section of the throughput benchmarking code,
const auto start_time = steady_clock::now();
while ( not bs.reader().is_finished() ) {
if ( split_data.empty() ) {
if ( not bs.writer().is_closed() ) {
bs.writer().close();
}
} else {
if ( split_data.front().size() <= bs.writer().available_capacity() ) {
bs.writer().push( move( split_data.front() ) );
split_data.pop();
}
}
if ( bs.reader().bytes_buffered() ) {
auto peeked = bs.reader().peek().substr( 0, read_size );
if ( peeked.empty() ) {
throw runtime_error( "ByteStream::reader().peek() returned empty view" );
}
output_data += peeked;
bs.reader().pop( peeked.size() );
}
}
const auto stop_time = steady_clock::now();Funny enough, the majority of the time is spent on output_data += peeked. These allocations and copying take up more than 70% of the time. Hence there is not much room for optimisation in the ByteStream class. This concludes Checkpoint 0.